
4D v13.4
Compilation diagnostic aids
- 4D Design Reference
-
- Compilation
-
- Overview
- Compiler window
- Compilation settings
- Compilation diagnostic aids
 Compilation diagnostic aids
Compilation diagnostic aids
There are three types of aids for the analysis and correction of databases:
- The actual analysis aid is provided by the symbol file. This table lets you find your way through your variables quickly. It is a valuable tool for interpreting the error messages reported by the compiler.
- The correction aid is provided by the error file which you can use as a text file.
- The execution aid or range checking provides you with an additional tool for monitoring the consistency and reliability of your applications.
Note: Significant assistance is also provided for the typing of variables by the automatic compiler methods — see Generate Typing.
The symbol file is a text type document whose length will depend on the size of your databases. By default, this file is not generated at the time of the compilation. To do so, you must check the corresponding option in the Database Settings (see Compilation options). When it is generated, the file is placed in the folder containing the database structure and is automatically named DatabaseName_symbols.txt.
The symbol file is displayed as follows when it is opened using a text editor:
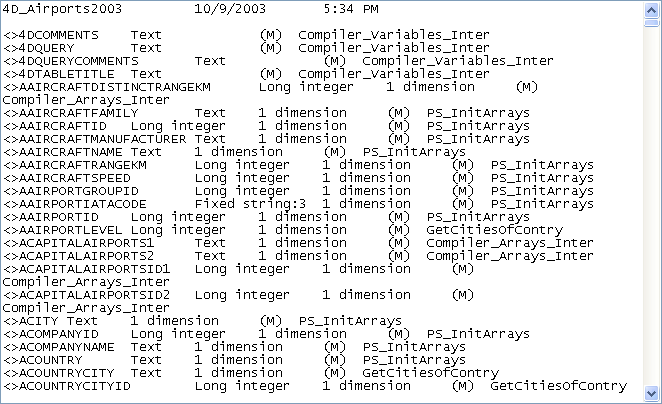
The header displays the name of the database and the date and time of the document creation. The document is divided into four parts:
- List of interprocess variables.
- List of process variables.
- List of local variables, in their method.
- Complete list of project methods and database methods with their parameters, if applicable.
These two lists are divided into four columns:
- The first column contains the names of process and interprocess variables and arrays used in your database. These variables are listed in alphabetical order.
- The second column contains the type of the variable. Types are set by compiler directive commands or are determined by the compiler based on the use of the variable. If the type of a variable cannot be determined, the column is empty.
- The third column lists the number of dimensions if the variable is an array.
- The fourth column contains a reference to the context in which the compiler established the type of the variable. If the variable is used in several contexts, the context mentioned is the one used by the compiler to determine its type.
- If the variable was found in a database method, the database method name is given as it has been defined in 4D, preceded by (M)*.
- If the variable was found in a project method, the method is identified as it has been defined in 4D, preceded by (M).
- If the variable was found in a trigger (table method), the table name is given, preceded by (TM).
- If the variable was found in a form method, the form name is given, preceded by the table name and (FM).
- If the variable was found in an object method, the object method’s name is given, preceded by the form name, table name, and by (OM).
- If the variable is an object in a form and does not appear in any project, form or object methods, nor any triggers, the name of the form in which it appears is given, preceded by (F).
Note: When compiling, the compiler cannot determine in which process a given process variable is used. A process variable can have a different value in each process. Consequently, all process variables are systematically duplicated as each new process is launched: it is thus advisable to watch out for the amount of memory that they will take up. Also, keep in mind that the space for process variables is not related to the stack size for the process.
The list of local variables is sorted by database method, project method, trigger (table method), form method, and object method, in the same order as in 4D.
This list is divided into three columns:
- The first column contains the list of local variables used in the method;
- The second column contains the type of the variable;
- The third column lists the number of dimensions if the variable is an array.
A complete list of your database and project methods is given at the end of the file, with the data types of their parameters and the returned result.
This information is presented in the following format:
Method name(parameter data types):result data typeYou can choose whether or not to generate an error file during compilation using an option located in the Database Settings (see Compilation options). When it is generated, the error file is automatically named DatabaseName_errors.xml and is created next to the structure file of the database.
Although the errors can be accessed directly via the compiler window, it can be useful to have an error file that can be transmitted from one machine to another, particularly in the case of several different developers working together in a client-server environment. The error file is generated in XML format in order to facilitate automatic parsing of its contents. It also allows the creation of customized error display interfaces.
The length of the error file depends on the number of errors and warnings issued by the compiler. When you open an error file using a text editor, it looks like this:
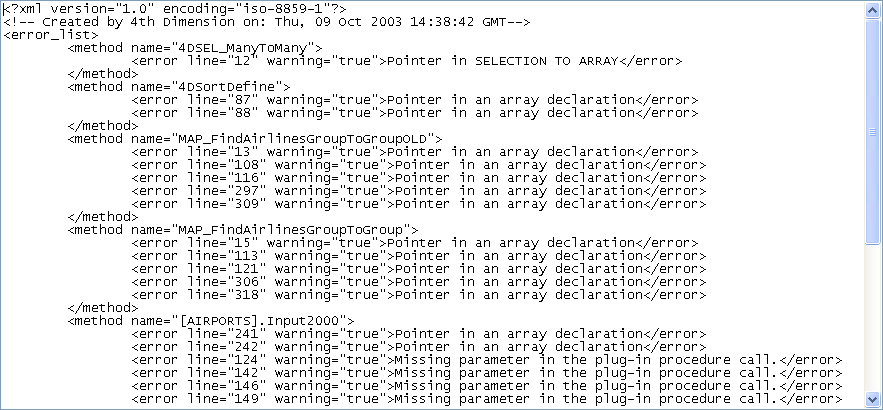
The structure of the error file is as follows:
- At the top of the file is the list of errors and warnings, sorted by method and in the order of their creation in 4D;
- In the ***General errors*** section, all the typing impossibilities and identity ambiguities are grouped together. These errors and warnings are listed using the following format:
- First, the line number in the method (0 indicates general errors);
- Second, the warning attribute indicates whether the detected anomaly is a warning (warning="true") or an error (warning="false");
- And third, a diagnostic that describes the error.
An error file may contain three types of messages:
- Errors linked to a specific line,
- General errors,
- Warnings.
These errors are displayed in context — the line in which they were found — with an explanation. The compiler reports this type of error when it encounters an expression in which it sees an inconsistency related to data type or syntax.
In the compiler window, double–click on each error detected in order to open the method concerned directly in the 4D Method editor with the line containing the error highlighted.
The list of syntax/typing diagnostic errors is found in the Error messages section of the 4D Language Reference manual.
These are errors that make it impossible to compile the database. There are two cases in which the compiler reports a general error:
- The data type of a process variable could not be determined.
- Two different kinds of objects have the same name.
General errors are so named because they cannot be linked to any specific method. In the first case, the compiler could not perform a specified typing anywhere in the database. In the second, it was unable to decide whether to associate a given name with one object rather than with another.
The list of general errors is found in the Error messages section of the 4D Language Reference manual.
Warnings are not errors. Warnings do not prevent the database from being compiled; they simply point out potential code errors.
In the compiler window, warnings appear in italics. Double–click on each warning to open the method concerned directly in the 4D Method editor with the line concerned by the warning highlighted. The list of warnings is found in the Warnings section of the 4D Language Reference manual.
You can disable certain warnings (see Disabling warnings during compilation).
Range checking is checked by default in the Database Settings (see Compilation options).
Whereas all the other options operate during the compilation process, range checking begins when you run the compiled database. That is, range checking messages only appear when your compiled database is running.
Range checking provides additional analysis with respect to the quest for logical and syntactical consistency which normally characterizes a compiler. During range checking, the compiler poses the following question: “Considering what you have requested, will the result that I am likely to obtain surprise you?”. Range checking is an “in situ” controller; it evaluates the status of objects in the database at a given time.
Here is how range checking works. Suppose that you declared the array MyArray as Text. The number of elements in MyArray may vary depending on the current method. If you want to assign the value “Hello” to element 5 of MyArray, you would write:
MyArray{5}:="Hello"If MyArray has five or more elements at that time, everything is fine. Assignment proceeds normally. However, if MyArray has less than five elements at that time, your assignment no longer makes sense.
A situation like this cannot be detected at the time of compilation since it presupposes the execution of the methods. The compiler would not know the circumstance in which this method is called. Only range checking enables you to monitor what is actually happening while your database is in use. In the above example, the compiler would display an execution error from within 4D. It is easy to see why range checking is especially valuable when arrays, pointers, and strings of characters are being processed.
The messages sent by the compiler when you request range checking are listed in the Range-checking messages section of the 4D Language Reference manual.
Even when range checking has been enabled, there may be some cases where you prefer that it not be applied to certain parts of code that are considered to be reliable. More particularly, in the case of loops that are repeated a great number of times, and when running the compiled database on older machines, range checking can significantly slow down processing. Insofar as you have the certitude that the code concerned is reliable and cannot cause system errors, you can disable range checking locally.
To do this, you must surround the code to be excluded from range checking with the special comments //%R- and //%R+. The //%R- comment disables range checking and //%R+ enables it again:
... //Range checking is enabled
// %R-
... //Place the code to be excluded from range checking here
// %R+
... //Range checking is enabled again for the rest of the methodNote: This mechanism will only operate when range checking is enabled.
Suppose you notice anomalies when running your databases. Before you start speculating about the possible sources of these problems, remember the assistance provided by the compiler.
Potential anomalies are:
- 4D displays its own error messages.
If possible, correct errors in your database according to instructions provided by 4D. If these are too general, compile your database again, making sure that the Range Checking option is enabled. Retest your database. At the location where the 4D message was displayed, you will see a more informative message from the compiler. - Your compiled database does not perform exactly like your interpreted database.
Take a closer look at the warning messages. - Number or String variables do not return expected values. Check the default typing options in the Preferences and examine the symbol file to check that all your variables are typed properly.
- Your database works in interpreted mode, but the application crashes in compiled mode. Make sure that you compiled the database using the Range Checking option and check to see whether your compiled database is using the same plug-ins as the ones you used when compiling.
Product: 4D
Theme: Compilation
warning, Contrôle d'exécution, %R***





